LLM Agent 직접 만들어보기 02
환경
window
4070 super
32G 메모리
컨텍스트 관리
저희가 사용하는 claude, chatgpt 를 생각해보면 대화의 맥락을 기억하고 이를 바탕으로 응답을 합니다. 불과 1년전의 chatgpt 를 생각해보면 맥락을 벗어나는 헛소리를 굉장히 자주 했습니다. 그러나 불과 1년 만에 이 기능이 비약적으로 상승하면서 사용자 체감이 굉장히 좋아졌습니다.
이는 context window 관리 기법의 발전이 있었기 때문인데요, context window 는 LLM 이 한번에 기억할 수 있는 텍스트의 최대 길이입니다. 실제로 각 서비스별 context window 를 비교해보면 다음과 같습니다.
- GPT-3.5: 4,096 토큰 (약 3,000 단어)
- GPT-4: 8,192 토큰 (약 6,000 단어)
- GPT-4 Turbo: 128,000 토큰 (약 96,000 단어)
- Claude-3: 200,000 토큰 (약 150,000 단어)
토큰이 길어질수록 n 제곱의 계산이 필요하기에, 응답 시간이 급격히 증가하고, 물리 메모리의 한계가 발생합니다. 이를 관리하기 위해서 sliding window, 중요도 기반 압축, 청킹 등의 기법이 있습니다. 저는 제 Agent 가 더 똑똑하기를 바라므로 Sliding window 와 중요도 기반 압축 기법을 적용해보겠습니다. 다음과 같은 dataclass 로 대화를 저장해봅시다.
전체 코드는 저장소에서 확인하실 수 있습니다.
1
2
3
4
5
6
7
8
9
10
@dataclass
class ConversationTurn:
turn_id: str # 고유 ID로 참조 가능
user_request: str # 사용자 요청만 분리
assistant_response: str # AI 응답만 분리
generated_code: str # 실제 코드만 분리
filename: str # 생성된 파일명
metadata: Dict # 추가 정보 (언어, 프레임워크 등)
이전 대화를 모두 LLM 에 넣는 방식은 LLM 을 아주 느리게 만듭니다. context 를 넣을 때 다음과 같이 요약해서 넣어줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def get_context_for_llm(self, session_id: str, include_code: bool = True):
# 1. 프로젝트 메타정보 (항상 포함)
context_parts.append(f"현재 프로젝트: {language}, {framework}")
# 2. 최근 3-5턴만 포함 (sliding window)
recent_turns = session.turns[-5:]
# 3. 코드는 요약만 포함 (토큰 절약)
for turn in recent_turns:
context_parts.append(f"요청: {turn.user_request}")
context_parts.append(f"응답 요약: {turn.assistant_response[:200]}...")
if turn.generated_code:
code_summary = self._summarize_code(turn.generated_code) # 코드 요약!
context_parts.append(f"생성 파일: {turn.filename} ({code_summary})")
그리고, 일반적으로 대화에 있어서 가장 중요한 첫번째 질문을 유지시켜줍니다.
1
2
3
4
if len(session.turns) > self.max_context_turns:
session.turns = [session.turns[0]] + session.turns[-(max_turns-1):]
프로그램을 구동시키고 결과를 확인해봅시다.
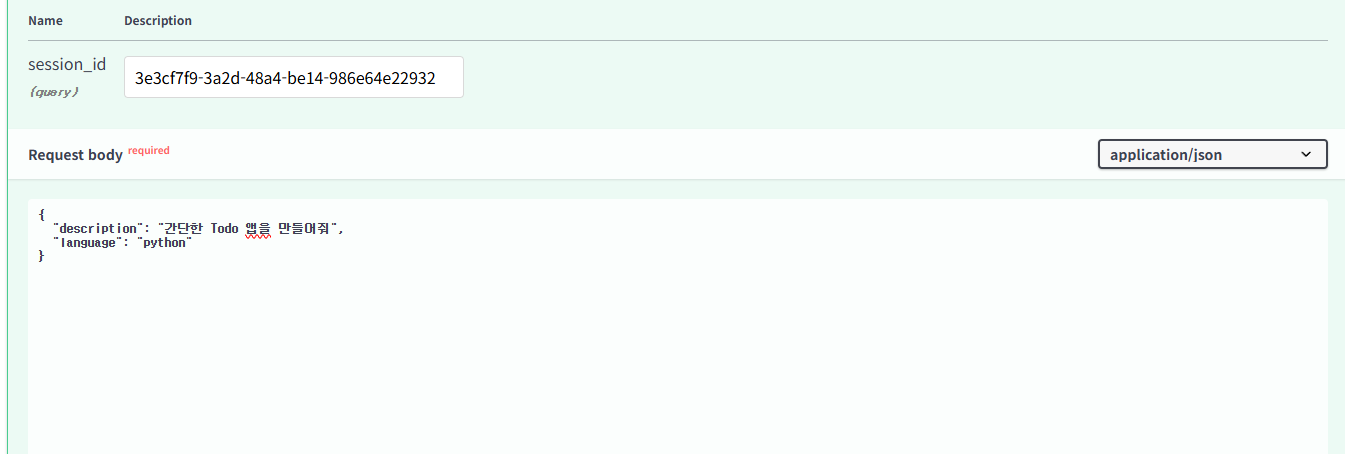
결과로 컨텍스트가 저장되는 것을 확인할 수 있습니다.
그 상태에서 이렇게 명령어를 입력하면
너가 만든 todo 앱의 주석을 추가해서 메서드의 역할을 알려줘
이렇게 결과가 나오는 것을 확인할 수 있습니다.
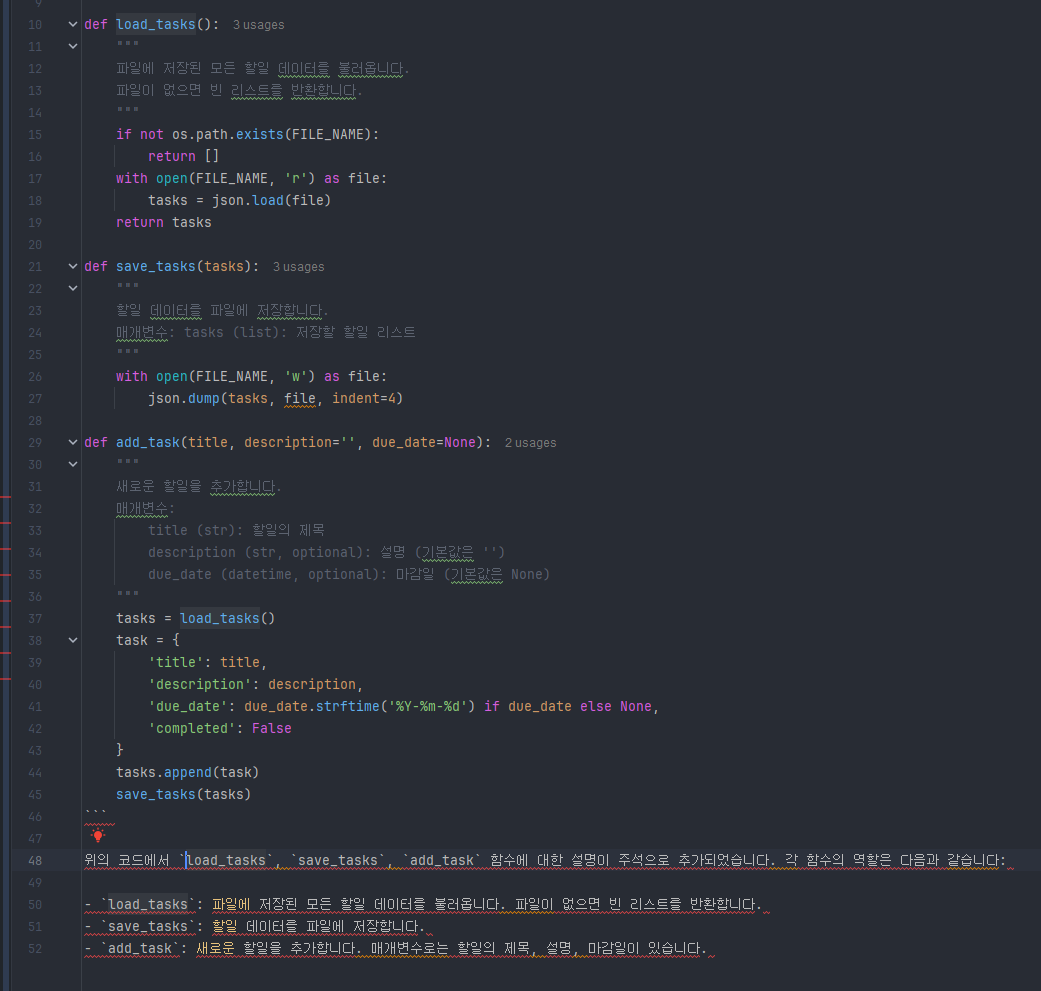
제 에이전트가 이제 컨택스트를 바탕으로 일을 할 수 있게 됐습니다!
다음
self improvements 기법을 적용해서 에이전트가 결과를 반복적으로 개선할 수 있도록 해보겠습니다.