사용자 수에 따른 규모 확장성
사용자 수에 따른 규모 확장을 어떻게 해야할지 고려해보자.
대규모 시스템 설계 기초 1장의 내용을 요약했습니다.
모두가 아는 모놀리틱 서버를 생각해보자. 브라우저에서 내가 만든 WAS 에 접속하면 어떤 일이 벌어질까?
DNS 조회 결과로 IP 주소가 나오면, 브라우저를 통해 IP 주소로 HTTP 요청을 보낸다.
요청을 받은 웹 서버에서는 요청을 처리한 후, 반환한다. 그 과정에서 데이터 처리를 할 것이다.
대부분의 데이터는 관계형 DB 에서 처리되지만, 비 관계형 DB 도 고려해볼만하다.
비 관계형 DB 는 이런 점에서 유리하다.
- 아주 낮은 응답시간이 요구됨
- 다루는 데이터가 비정형이라 관계형 데이터가 아님
- 데이터를 직렬화하거나 역젹렬화할 수 있기만 하면 됨
- 아주 많은 양의 데이터를 저장할 필요가 있음
이제 사용자가 많아졌다. 규모 확장을 고려해야 한다. 규모 확장에는 scale up 과 scale out 이 존재한다. scale up 은 장애에 대한 자동 복구 방안이나, 자동복구 방안을 제시하지 않는다.
Scale out
Scale out 을 하기로 결정했다. 여러 대로 구성된 서버에 부하 분산을 위해 로드밸런서를 도입해야 한다.
- 사용자는 로드 밸런서의 공개 IP 주소로 접속하고, 어떤 서버로 처리되는지 알 수 없다.
데이터베이스 다중화도 고려할 수 있다. 읽기 DB 와 쓰기 DB 를 나누는 방법을 생각해보자.
- 쓰기 연산은 마스터에서만 지원한다. 읽기 연산은 slave 에서만 지원한다.
- 읽기 연산이 병렬 처리될 수 있다.
- 데이터를 지역적으로 떨어진 여러 장소에 다중화하므로 장애에 강하다
- 한 DB 에 장애가 발생하더라도 다른 서버에 있는 데이터를 가져와 사용할 수 있다.
캐시와 CDN
응답시간을 개선하기 위해서는 캐시와 CDN 의 사용을 고려해보자
캐시는 DB 에서 가져온 데이터가 잠시 보관되는 곳이다. 자주 사용되는 데이터를 DB 에서 가져올 필요 없이 바로 내려주자.
캐시를 보관하다보면 꽉 찰 수도 있고, 더 이상 캐시가 DB 에 있는 정보와 달라 유효하지 않을 수 있다.
따라서 캐시 만료 정책을 마련해야 한다.
- facebook memcached 참고
- https://www.youtube.com/watch?v=m4_7W4XzRgk&t=5s
- 다량의 memcache 클러스터를 구축하기 위한 방법을 설명
- https://timilearning.com/posts/mit-6.824/lecture-16-memcache-at-facebook/
- 캐시는 결국, 언제 캐시가 유효하지 않은가를 알아내는 것이 어려움
- db commit log 를 바탕으로, 캐시의 invalidate 를 noti 하고, 이는 layer 를 거쳐서 말단 캐시 서버로 전파됨
- https://www.youtube.com/watch?v=m4_7W4XzRgk&t=5s
- 데이터 방출 전략도 잘 세워야 한다
- 캐시가 꽉 찬 경우 어떤 전략을 사용할 것인가?
- LRU
- LFU
- 캐시가 꽉 찬 경우 어떤 전략을 사용할 것인가?
CDN 은 요청 정보에 근거하여 정적 데이터를 캐싱하는 것이다.
Message Queue
수평적으로 확장하기 위해서는 상태 정보(세션 데이터)를 웹 계층에서 제거해야 한다.
stateless 해야 한다는 의미이다.
- 상태 정보를 서버에서 유지하는 경우엔, 로드밸런서의 고정 세션 방식을 이용할 수 있는데 이는 로드밸런서에 부담을 준다.
메시지 큐를 이용해 시스템의 컴포넌트간 의존 관계를 분리할 수 있다.
- 사진 보정 작업을 비동기로 처리하기 위해 MQ 를 사용할 수 있을 것이다.
데이터베이스 샤딩
데이터베이스를 확장하기 위해서 샤딩을 할 수 있다. 샤딩은 데이터베이스를 샤드라고 부르는 작은 단위로 분할하는 기술을 일컫는다. 예를 들면, user_id % 4 를 해시 함수로 사용하는 샤드를 정할 수 있다.
샤딩 키를 적절하게 정해서, 데이터를 고르게 분할 할 수 있어야 한다.
- 데이터의 재 샤딩 : 데이터가 너무 많아져서 하나의 샤드로는 감당하기 어렵거나, 샤드 간 데이터 분포가 균등하지 못할 때.
- 유명인사 문제 : 핫스팟 키 문제라고도 부른다.
- 특정 샤드에 질의가 집중되서 서버에 과부하가 걸리는 문제다.
- 조인과 비정규화 : 여러 샤드에 걸친 데이터를 조인하기가 힘들어진다. 데이터베이스를 비정규화해서 하나의 테이블에서 질의가 수행되는 방법을 고려해야 한다.
- 넷플릭스에서 지역별로 분리된 데이터를 일치화하기 위해서 어떻게 했는지
- https://netflixtechblog.com/active-active-for-multi-regional-resiliency-c47719f6685b
- 카산드라를 사용해, 다중 데이터 센터의 데이터 비동기 복제를 적용
- 넷플릭스에서 지역별로 분리된 데이터를 일치화하기 위해서 어떻게 했는지
- 유명인사 문제 : 핫스팟 키 문제라고도 부른다.
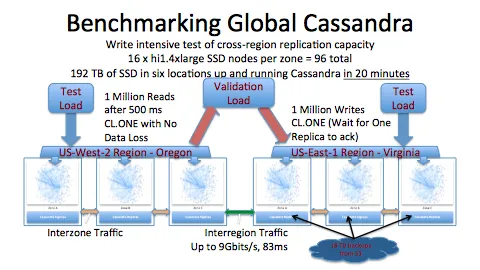
시스템 규모 확장을 위한 기법은 정리하자면 다음과 같다.
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 많은 데이터를 캐시할 것
- 여러 데이터 센터를 지원할 것
- 정적 콘텐츠는 CDN 을 통해서 서비스할 것
- 데이터 계층은 샤딩을 통해 규모를 확장할 것
- 각 계층은 독립적 서비스로 분할할 것
- 시스템을 지속적으로 모니터링하고, 자동화 도구들을 활용할 것