spring cloud gateway 에서 사용자 요청 로그를 남겨보자
Spring Cloud Gateway 에서 사용자 요청 로그 남기기
배경
Spring Cloud Gateway 를 사용하면 요청을 각각의 Micro Service 로 알맞게 전달해줄 수 있습니다. 각 마이크로 서비스별로 로그를 남기는 것도 좋지만, 사용자 요청 로그를 남기는 포인트는 공통화하면 유지 보수에 용이하기에, 게이트웨이에서 사용자 요청 로그를 남길 수 있도록 하는 방법을 공유드리고자 합니다.
설계
작업에 앞서서 다음과 같은 시퀀스 다이어그램을 그렸습니다. 대략적인 플로우는 다음과 같습니다.
- MSA 서비스에서 사용자 인증 처리 후, 로그를 남길 때 사용자를 식별하기 위한 식별자를 내부용 header 에 추가한다.
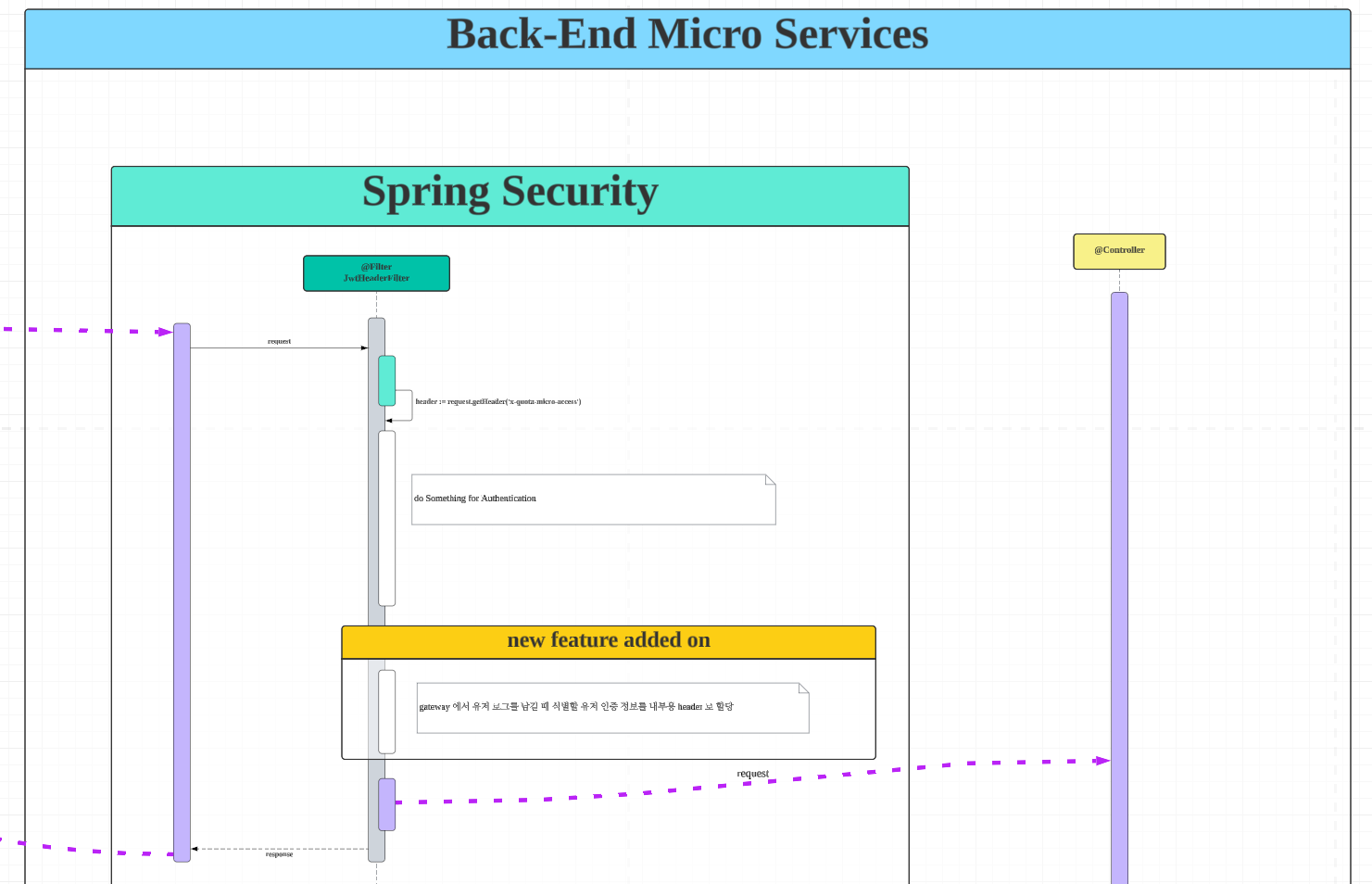
- Gateway 에서 요청을 반환하는 시점에 식별용 header 값을 추출하고, request 의 header 값, path 등 필요한 정보를 dynamodb 로 쌓는다.
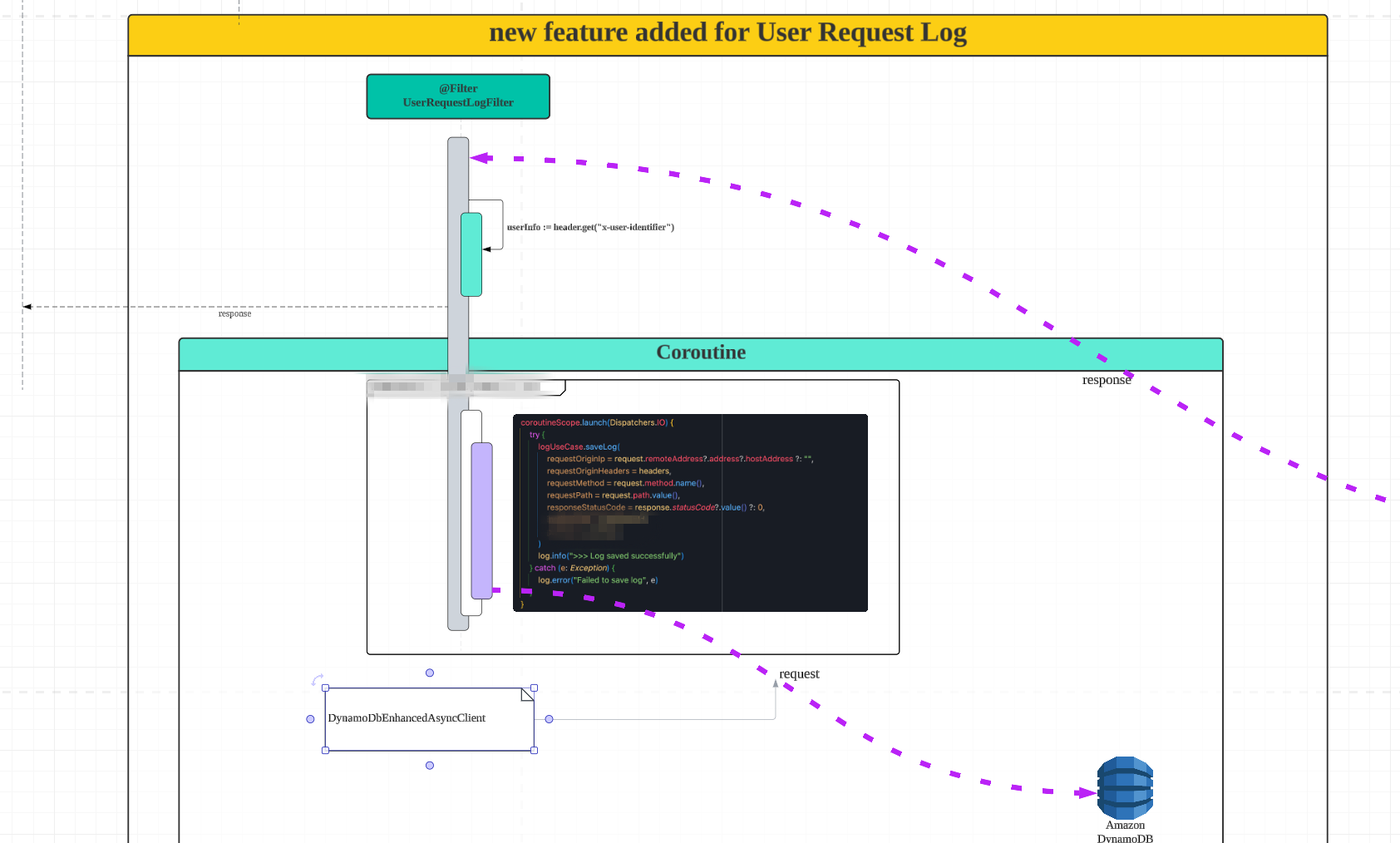
시퀀스 다이어그램의 이해가 어렵다면, 설계 훈련 - 시퀀스 다이어그램을 참고하셔도 좋을 것 같습니다.
코루틴
Spring Cloud Gateway 는 Netty 와 Webflux 를 사용합니다. 로그 처리가 본래의 응답 처리에 영향을 끼쳐서는 안되기에 chain.filter 와는 별개로 로깅을 처리해야 합니다. webflux 에서 그대로 사용해도 되지만 저는 코루틴을 사용해서 다음과 같은 코드를 구성했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
suspend fun saveLog(...)
// 로그를 남기기 위한 부분
chain.filter(exchange)
.then(
Mono.defer {
coroutineScope.launcn(Dispatchers.IO) {
logUseCase.saveLog(...)
}
}
)
그렇다면 코루틴을 사용한 이유는 무엇일까요?
- 가독성이 좋기 때문입니다. 다음은 webflux 로 작성된 코드입니다.
1
2
3
4
5
6
7
8
9
10
// Filter에서 사용
return chain.filter(exchange)
.then(
logUseCase.saveLog(exchange.request, exchange.response)
.onErrorResume {
Mono.empty()
}
)
에러 처리를 위해서 별도의 체이닝이 필요함을 확인할 수 있습니다. 그에 반에 코루틴은 일반적인 동기 코드처럼 작성이 가능합니다.
- 디버깅이 용이하기 때문입니다. Webflux 를 사용해보신 분들은 아시겠지만, 에러가 발생했을 때 스택 트레이스가 굉장히 복잡합니다.
1
2
3
4
5
6
7
8
// WebFlux 스택트레이스 예시
java.lang.IllegalStateException: Error occurred
at reactor.core.publisher.Mono.lambda$map$2(Mono.java:2432)
at reactor.core.publisher.FluxMap$MapSubscriber.onNext(FluxMap.java:106)
at reactor.core.publisher.Mono$MapSubscriber.onNext(Mono.java:2432)
// 많은 리액터 내부 스택들
이에 반해서 코루틴은 훨씬 직관적이고 단순합니다.
1
2
3
4
5
6
7
Exception in thread "main" java.lang.IllegalStateException: Failed to process
at MainKt.processData(Main.kt:15)
at MainKt.process1.invokeSuspend(Main.kt:10)
at MainKt.main(Main.kt:5)
Caused by: ...
브레이크 포인트로 코드의 실행 흐름을 추적할 때도 용이합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 코루틴 - 순차적 실행 흐름
suspend fun process() {
// 각 지점에 브레이크포인트를 걸고 값을 확인하기 쉬움
val data = fetchData()
val processed = processData(data)
saveResult(processed)
}
// WebFlux - 체인 형태의 실행 흐름
fun process(): Mono<Result> {
return fetchData()
.flatMap { data -> // 중간 값 확인이 더 복잡
processData(data)
}
.flatMap { processed ->
saveResult(processed)
}
}
따라서 코루틴을 사용해서 로그를 남기도록 구현했습니다.
이벤트 기반 아키텍쳐를 사용하지 않은 이유?
로그 시스템의 베스트 프렉티스는 일반적으로 이벤트 기반 아키텍쳐입니다. 예를 들면 게이트웨이에서 카프카에 로그 생성 이벤트를 보내고, 별도의 로그 서버에서 해당 이벤트를 수신해서 로그를 남기는 형식입니다.
그러나 저의 경우에는 게이트웨이에서 직접 로그를 남기는 것으로 구현했는데요, 이는 다음과 같은 장점이 있기 때문입니다.
- 구현이 간단합니다. 카프카도 필요없고, 별도의 로그 서버도 필요 없고, 로그 서버의 구성을 위한 eks 설정도 필요 없습니다.
- 코루틴을 사용해서 게이트웨이에서 직접 로그를 남겨도 실제 자원 사용량의 차이는 미미합니다. 실제로 k6 를 이용한 부하테스트를 해봤습니다. 로그를 남기기 전 후의 성능을 비교해본 것인데요. 저희 서비스의 최대 규모 동시 접속자의 * 2 배로 vuser 를 가정하고 부하 테스트를 했음에도 로그를 남기기 전과 후의 TPS 차이는 유의미하게 있지 않았습니다. 뿐만 아니라 메모리의 사용량도 유의미하게 증가하지는 않았는데 이는 아마 Dynamodb 의 입력 속도가 매우 빠르다는 점 덕분인 것 같기도 합니다.
결론
스프링 클라우드 게이트웨이, DynamoDB, 코루틴을 사용해서 간단히 사용자 로그를 남기는 시스템을 구축해봤습니다. 물론 이벤트 기반 아키텍쳐가 아니기에 로그가 유실될 수도 있습니다. dynamodb 에는 write 속도를 지정할 수 있는데, 단일 테이블에 지정된 write 속도보다 많인 쓰기 요청이 들어오면 해당 요청에 대한 로그가 유실됩니다.
물론, 저희 같은 경우는 서비스 최고 부하 기준 * 5 정도로 dynamodb 의 쓰기 한계를 설정해두긴했지만, 묵시적인 유실 가능성이 있다는 점은 불안 요소일 수 있습니다. 이런 제약사항들이 있지만 구현이 간단하고 게이트웨이 서비스의 자원만으로도 일정 수준의 로깅을 구현할 수 있다는 점에서 훌륭한 ‘가성비’를 지녔다고 생각합니다. 다음에는 body 를 추가해서 로깅하는 부분을 공유드리도록 하겠습니다. 감사합니다.